-
Полоса прокрутки (2)
Небольшое продолжение про Ютуб — и больше поднимать эту тему не буду.
Всякими махинациями я добился того, чтобы полоса была под видео, а не на нем. Для этого классу
ytp-chrome-bottomдобавляется свойствоbottom: -60pxили около того. Но проблема пришла откуда не ждали, и даже не одна.Дело в том, что тулбар появляется только когда наводишь курсор на плеер. Так вот: если тулбар вне плеера, то наведение мыши на него ничего не дает — он остается невидимым. Простыми словами, перестает работать.
Я такой думаю: наверное, на тулбар вешается класс
hiddenили похожий. Сейчас поменяю этот класс, чтобы он был всегда видим и победю систему. Оказалось, видимость определяется не классом, а средствами JavaScript.Тогда я сделал так: растянул плеер, чтобы он охватывал тублар даже после смещения. Это помогло: при наведении на тулбар он появляется. Однако теперь не работают кнопки. Ощущение, будто где-то есть невидимый div, который перехватывает клики. Из-за смещения тулбара они идут мимо него, и ничего не работает.
Ну и в целом сложность: штук двадцать вложенных дивов
yt-player→yt-main-container→yt-main-inner→yt-video-container→yt-video-nodeи так далее. Каждый что-то перехватывает и наследует. Дебажить этот цирк — то еще удовольствие.Так что переносом тулбара вверх я пока и ограничусь. Слишком напряжно этим заниматься. Сложность Ютубного плеера колоссальная: там годы легаси и костылей, чтобы работать во всех браузерах, трекать, показывать рекламу, плашки, рекомендации и так далее. Задача мне не по зубам, признаю поражение.
-
Полоса прокрутки
Некоторое время назад я жаловался на плеер Ютуба, мол, полоса прокрутки и кнопки залезают на видео. На это можно повлиять при помощи своего css-файла. Для Фаерфокса и его форков инструкция такая:
-
Определить папку с профилем. Для этого нажать Help -> More Troubleshooting Information -> Profile Folder -> Show in Finder
-
Создать в ней папку chrome
-
В ней создать файл
userContent.cssс таким содержанием:
@-moz-document domain(youtube.com) { .ytp-chrome-bottom { position: relative !important; bottom: -15px !important; } }-
Зайти в
about:configи задать свойсвоtoolkit.legacyUserProfileCustomizations.stylesheetsвtrue -
Перезапустить браузер.
В результате тулбар окажется сверху с зазором в 15 пикселей. Картинку прилагаю:
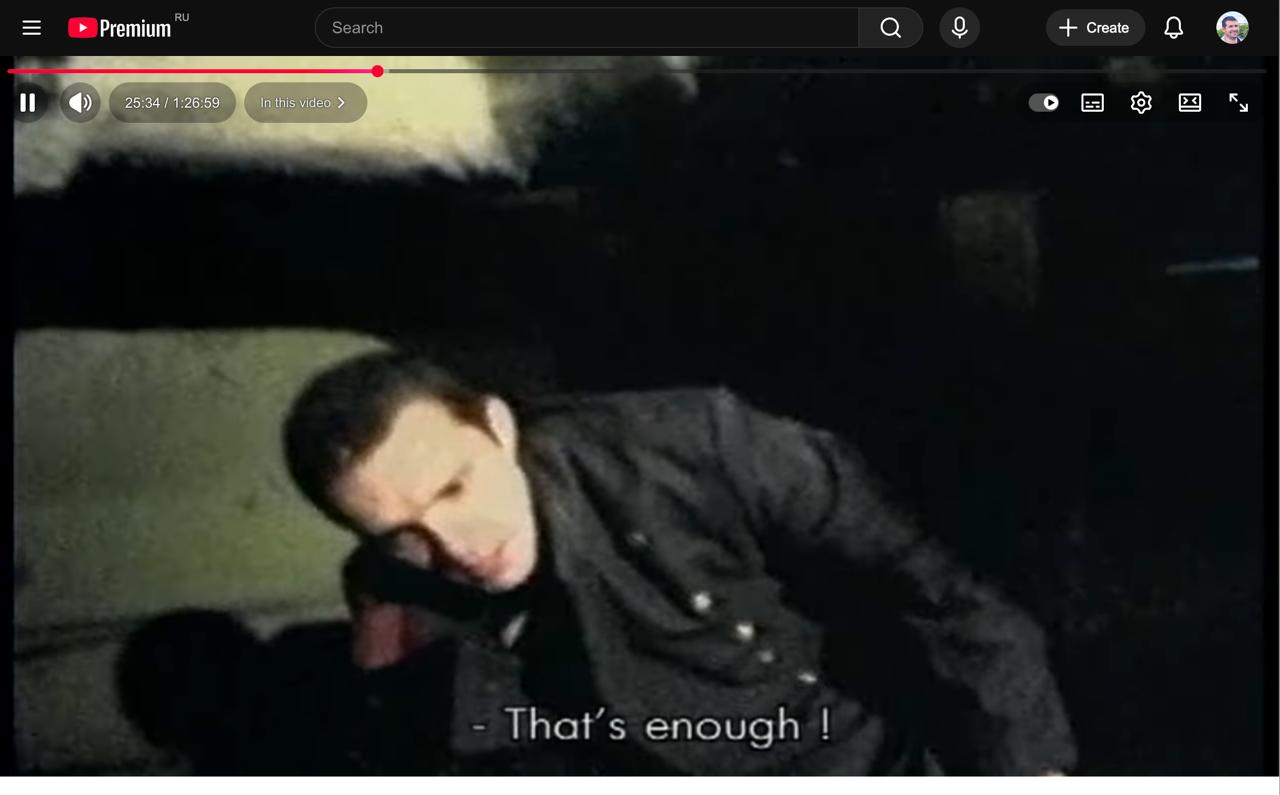
Мысли следующие: пока настраивал папки-файлы, поразился этому дурдому. Почему ради простой задачи нужно совершать пять шагов? Неужели нельзя сделать примитивный textarea, куда вводишь текст и он сохраняется в файл? Почему браузер нужно перезагружать? Почему папка называется “Хром”? При чем тут хром? Какая-то жесть.
В общем, когда стили заработали, я удивился как бухгалтер, у которого сошелся годовой отчет.
Впечатления от новой полосы интересные. Чувство такое, что вместо 90% контента теперь видишь все 100%. Внезапно, надписи внизу читаются; у людей есть колени и ноги; у ведущего в углу кадра есть лицо. Раньше ничего этого не было, а теперь — пожалуйста.
Могу спокойно читать субчики в “Зеленом слонике”, а раньше не мог. То-то же.
Для Хрома и форков инструкции нет, но полагаю, найдутся расширения.
Ни в коем случае не продавливаю свое решение — по-хорошему его надо улучить. Но какую-то свежесть оно дает, попробуйте.
-
-
Оружия черепашек-нинздя
Разговаривал с одним человеком и выяснил, что он не знает, какие оружия у черепашек-нинздя. Это должен знать каждый, и я не сомневаюсь, что и вы знаете. Просто на всякий случай повторю.

Итак, первый уровень, изи: Леонардо, который в голубой повязке, владеет двумя мечами. Это всем понятно.
Второй уровень, нормал: что у Микеланджело, который в оранжевой повязке? Это нунчаки: две палки на цепи, которыми проще убить себя, чем противника.
Теперь третий уровень, хард: что у Донателло, который в фиолетовой повязке? Простолюдин скажет, что у него палка, и от этого хочется плакать. Это бо! – или, чтобы было понятнее, шест бо. Посох из металла или с его элементами, чтобы не сломаться и сильнее бить противника. Бо полезен в бою, в быту, в походе, словом, универсальная для Востока вещь.
Последний уровень, найтмеар: что у Рафаэля, черепашки в красной повязке? Когда говорят, что трезубец, хочется кататься по полу от отчаяния. Это саи. С-а-и! Один сай, два сая, многое саев. Гугл-док не понимает и предлагает замену, но вы-то понимаете! Такие кинжалы с двумя лепестками по краям. Идея в том, чтобы принять меч противника между зубцами и резко повернуть. Твой рычаг больше, чем у противника, и он теряет оружие.
Все это я пишу по памяти безо всяких Википедий, и знал это лет с семи. А вот как без этого можно жить – я не понимаю. Молодежь пошла не та, зумеры не хотят работать и вообще все плохо.
-
Дизайн REST API
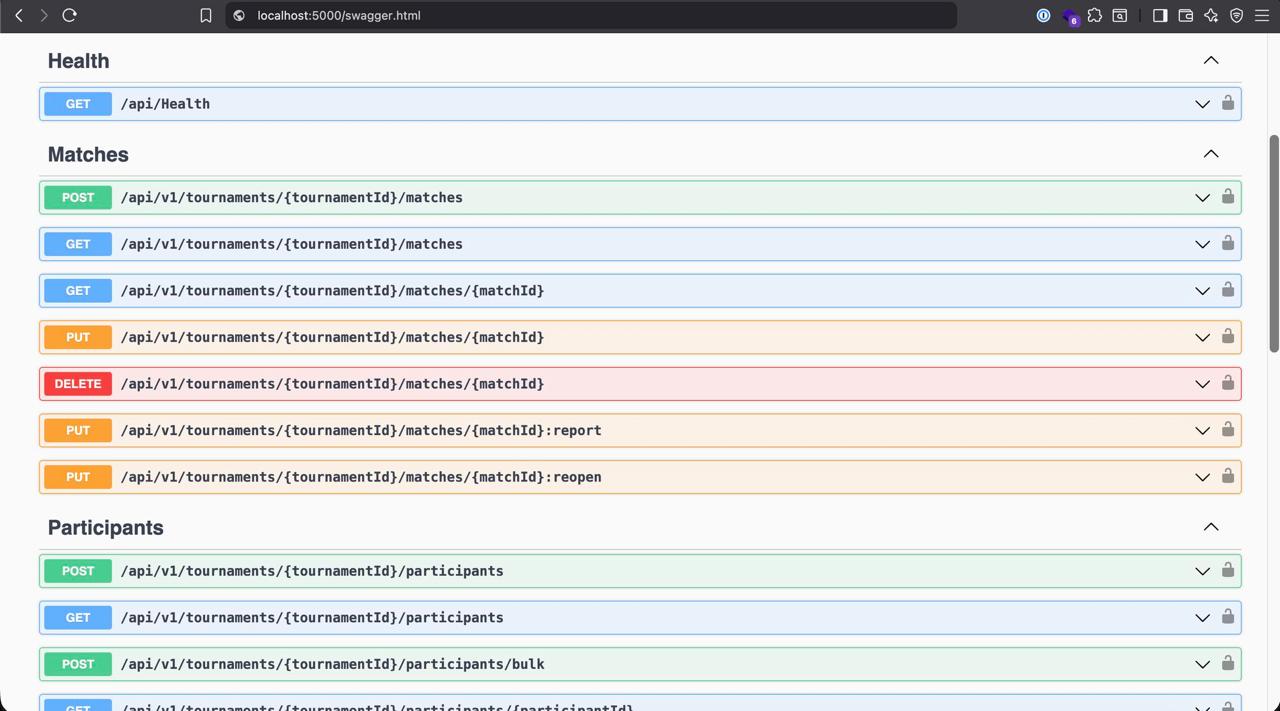
В Линкед-ине хвастает человек: мол, нейросеть задизайнила рест-апишку. Прикладывает скриншот сваггера. Я смотрю на него и киваю: да, все на месте, все как у современного разработчика. А еще я понимаю, что на скриншоте, как в капле воды, собрано все то, за что я не люблю рестовые апишки.
Во-первых, версия
v1в урле. Она всегда меня забавляла. Я работал во многих стартапах, и ни один из них не сменил версию. Гораздо чаще стартапы закрываются и продаются. Я считаю, апишка должна быть одна, и со временем какие-то методы добавляются, какие-то снимаются с обслуживания. А в той нумерации, что на скриншоте, слишком много пафоса. Примерно как объявить счетчик с шестью нулями для значения, которое в лучшем случае достигнет двойки. Даже если предположить, что появится новая апишка, просто сделай другой урл:/api/grpcили/api/graphql.Далее, иерархия. Те апишки, которые работают с матчем, требуют код турнира. Нужно передать две айдишки: турнира и матча. Зачем? Разве может матч относиться к разным турнирам? Это банальная избыточность, и делается она ради красоты. Должен передаваться только матч, а по нему легко найти турнир и проверить права.
Еще одна забавная вещь: метод
PUTне может покрыть все изменения, поэтому в ход идут костыли: частички:report,:reopenна конце урла. Это некрасиво, потому что по-хорошему операция определяется HTTP-методом, а тут урлы. Тот случай, когда шубу заправляют в трусы, а она не лезет.Ну и расцветка Сваггера как у цыган: зеленый, голубой, оранжевый, красный… все собрали.
На мой взгляд, нормальная апишка должна быть по принципу RPC. Один урл с двумя параметрами:
actionиparams. Метод один – POST. Внутри словарик с функциями и схемами, по которому раскидываются запросы. Все. Документашка со схемами строится одной командой.Апишка – довольно простая вещь. Она не должна быть сложной и требовать разного тулинга. Тот REST, что имеем сегодня – это вавилонская башня на ровном месте. Как и в библейской истории, разработчики сами не понимают друг друга. Но продолжают и продолжают строить эту башню.
-
Просто берите SQLite
Тезис к размышлению: при помощи Postgres и SQLite можно решить (почти) все насущные задачи. Без распределенных кэшей, очередей, облачных паб-сабов и так далее.
Насчет Постгреса все ясно: я уже писал о нем отдельно. А что SQLite?
Замечаю одно и то же: иной раз требуется хранить в памяти какие-то данные. Сначала это словарь вида id -> сущность. Потом нужен поиск по полю сущности. Строится обратная мапа поле -> список сущностей. Потом нужная вторая сущность и перекрестные ссылки. Код превращается в ад.
Наблюдаю такое в трех сервисах. Ребята читают из файлов сущности, строят прямые мапы, обратные, перекрестные… потом ходят по ним безо всяких проверок, ловят нулы и странные результаты.
А решение простое: запиши свое барахло в SQLite! Из коробки получишь индексы, поддержку целостности, универсальный интерфейс, поддержку JSON и миллион расширений. И появился SQLite не вчера, а старше иного разработчика. И тестов под него написано чуть ли не сотня тысяч.
SQLite отлично подходит, чтобы не шатать боевую базу. Забрал данные, сложил себе и делаешь что хочешь. Можно делать ночную выгрузку, чтобы всякие отчеты принимали SQLite, а не ходили в прод.
Если данные не помещаются в памяти, можно скинуть их на диск. Красота же?
Есть и другие рецепты использования SQLite, например использовать его для обмена данными. Каждый, кто сталкивался с сериализацией, знает, какая это боль и сколько в ней подводных камней. Один из способов их обойти – кидаться файлами SQLite.
За счет SQLite можно выкинуть просто нелепое количество кода и самописных решений. Разумеется, не всегда – но по моему опыту, очень-очень часто.
-
О кложурных редьюсерах
В последнее время я немного подавлен работой. Делаю одну задачу уже много месяцев, при этом она довольно тупая и бестолковая. Омрачает то, что в процессе я нахожу баги, порой довольно серьезные. Чувствую себя так, словно заставили идти через поле коровьих лепешек.
Часть багов связана с инфраструктурой и очередями задач. Пересказывать их довольно скучно, и вряд ли вам будут интересно. Но один бажок на тему Кложи и параллельных вычислений мне запомнился, и сейчас его расскажу.
Как вы знаете, Кложа хороша своими коллекциями – это прямо алмаз, одно из немногих утешений в айти. Вместе с коллекциями прилагаются штук триста функций: всякие
map,reduceи так далее, включая экзотику.Начиная с какой-то версии в Кложу завезли параллельные map и reduce. Пакет называется
clоjure.core.reducers. Сигнатуры параллельных функций почти идентичны оригиналам. Идея в том, что ты такой хоп – заменилreduceнаr/reduce, и вычисления раскидались по ядрам. Нашлись коллеги, которые, не читая документации, так и сделали – а я пожал их плоды.Есть огромных файл, где каждая строка – джейсончик. Нужно построить мапу
{id -> entity}, чтобы быстро дергать из нее сущность по айдишке. Скажем, в Питоне это делается так:{entity["id"]: entity for entity in file.read_lines() }В Кложе это тоже решается тремя строчками. Но коллега использовал не простой reduce, а который параллельный. Логика такова: коллекция большая, пусть колбасится параллельно. И вот я вызываю функцию, которая строит эту мапу, и замечаю – в ней нет половины ключей. Пропали. Что такое?
Дебажил я передебажил и выяснил вот что.
В документаци
clоjure.core.reducersнаписано, что коллекции не всегда обрабатываются параллельно. Критериев несколько, например коллекция мала и нет смысла ее делить. Но главный критерий таков: коллекция не должна быть ленивой. А те коллекции, что коллеги читают из файла, ленивы. Это нормально, потому что файл огромный и читать в память все разом нельзя. Но получается, что вся параллельность идет псу под хвост – параллельныеr/mapиr/reduceсводятся к последовательным аналогам.Другими словами, параллельной обработки никогда не было. Вызовы есть, но эффекта нет. Никто этого не замерял и не проверял.
Почему же у меня возникла ошибка? Дело в том, что я передал вектор – не ленивую коллекцию. Она попадала под критерии параллельности, и произошло вот что. Пакет
clоjure.core.reducersиспользует подходForkJoin. На этапеForkколлекция бьется на части, и каждая часть обрабатывается в своем потоке. Получаются, скажем, два словаря{id -> entity}для каждой части. Далее наступает фазаJoin– их нужно объединить. Функцияr/reduceпринимает дополнительную функцию для сборки финального результата, но ее не передали. А если ее нет, вызывается редуцирующая функция. Она приняла два словаря и неправильно их обработала, в результате чего пропала половина данных. Нужно было передать туда функцию merge, но никто не знал, для чего это в принципе.Когда я это исправил, нашел еще один косяк у себя самого. Когда записи индексируют по
id, с объединением проблем нет, потому что ключи уникальны. Но представим, что выполняется группировка по какому-то рейтингу. В этом случае результат такой:{"a" [1 2 3], "b" [5 4 1]}Если дать эту задачу на параллельное вычисление, они могут вернуть что-то такое:
{"a" [1 2], "b" [5]} {"a" [2 3], "c" [11]}То есть и в первом потоке был такой ключ, и во втором. Если тупо объединить словари, получится вот что:
{"a" [2 3], "b" [5], "c" [11]}, то есть из “a” пропадет 1. Ошибки не будет, все пройдет молча, и догнать причину будет сложно. Правильная функция объединения будет такой:
(partial merge-with into)С ней получим результат
{"a" [1 2 3], "b" [5], "c" [11]}.Ради интереса прошелся по коду коллег: почти везде используются ленивые коллекции. Это значит, что параллельные вычисления банально не работают. Я хотел поправить, но плюнул: давайте-ка сами.
В сухом остатке:
-
человек подключил либу для параллельных вычислений
-
вычисления всегда протекали последовательно
-
при попытке вычислить что-то параллельно получали ошибочный результат. Исключения нет, все тихо, ищи сам.
В Гарри Поттере была фраза: “не доверяй тому, что мыслит, если не знаешь, где у него мозги”. Я бы перефразировал: не доверяй быстрым библиотекам, если не понимаешь, за счет чего достигается скорость. Реалии таковы, что в погоне за скоростью срезают углы. Это ни хорошо ни плохо, это факт, который нужно знать.
Внедряя параллельные вычисления, уделите хотя бы толику внимания тому, какие сюрпризы вас ожидают.
-
-
Обновление Ютуба

Гугл грозился обновить плеер в Ютубе, и вот это случилось. До этого новый интерфейс появлялся у меня пару раз, но быстро пропадал. Подозреваю, его откатывали из-за ошибок. Но теперь все исправили, и он с нами надолго.
Напомню, в чем проблема. Новая панель почти в два раза выше, чем прежде. Приложил к экрану линейку: была сантиметр, стала 18 миллиметров. При этом все кнопки старые, нет ни одной новой. Просто теперь они собраны в капсулы, а еще им добавили отступы.
Новый воздушный интерфейс на редкость уродский. Слева и справа группы кнопок, а в центре — полоса перемотки. Она, словно барьер, режет видео пополам. Она залезает на лица ведущих, которые по недоразумению поставили их снизу.
Если когда-нибудь вы смотрели ролики по изучению языков, то знаете — субтитры добавляют на этапе монтажа. Обычно их ставят внизу, чтобы не заслонять лица. Еще во времена старой панели это было проблемой: поставил на паузу, чтобы прочитать — но панель загораживает. Приходится двигать мышкой, кликать на посторонние элементы, чтобы перенести фокус. А теперь панель стала еще выше!
Я как-то смотрел видео одного человека (неважно о чем, не хочу раскрывать увлечения). Судя по всему, он японец и не говорит по-английски, хотя читает и пишет отлично. Он записывает ролики и добавляет в них текстовые комментарии. С новой панелью прочитать их во время паузы невозможно. Полоса перечеркивает буквы.
Я не понимаю, почему панель должна налезать на видео? Кто сказал, что видео — это область, где можно ставить кнопки, бегунки и прочее? Нельзя! Оставьте видео в покое! На нем ничего не должно быть.
Опять же, не понимаю, почему нельзя сделать опцию “панель снизу”? Это буквально пара мест в CSS, чтобы сместить блок вниз.
В общем, главная медиа-площадка планеты — отличный пример того, как делать не нужно.
-
Postgres в Телеграме
Лишний раз убедился, что писать на чужих площадках — гиблое дело.
Где-то три года назад я вступил в группу Postgres в Телеграме; там было 11 тысяч пользователей. Только начал писать — какие-то тролли наставили кучу дизлайков. Я даже не понял: это заговор или что? Вышел.
Полгода назад снова вступил в эту группу, там уже 14 тысяч пользователей. Отвечал на вопросы, помогал. Сегодня ответил на сообщение админа — совершенно нейтрально, по существу — получил бан на час.
Что ж, если не хотите меня, то так и быть. “Мэссадж понятен даже идиоту” (с). Вышел, и третьему разу уже не бывать.
Вот за этим и хорошо иметь свой блог или канал — можно писать все, что хочешь. Поэтому я не вступаю в закрытые каналы, группы, клубы и прочие “илитные” тусовки. Там ты всегда под кем-то, а это рано или поздно выйдет боком.
-
Записи в Джаве
Кажется, с версии 17 в Джаве появились рекорды — они же записи. Клевая вещь, коротко про нее расскажу.
Запись — это класс с набором барахла, которое раньше нужно было писать руками. Только теперь это барахло производит компилятор. Например, если объявить запись с двумя полями:
public record User(name String, age int) {}, то получим класс с полями
nameиint. Однако:-
все поля финальные, их можно задать лишь однажды и никогда — изменить;
-
у класса готовый конструктор, в котором поля следуют в том порядке, что и в объявлении;
-
у класса готовые методы
.name()и.age(), которые ведут себя как геттеры; -
у класса свой метод
.hash(), который учитывает все поля; -
свой метод
.equals(), который сравнивает записи по значениям; -
удобный
.toString(): напечатав запись, вы увидите значения полей, а не[foo.bar.User x00x0s0ds](или что там печатает Джава по умолчанию).
Есть и другие плюсы, не помню все досконально.
Получается, на ровном месте появились нормальные неизменяемые классы. Всего-то двадцать лет прошло или около.
Хорошая привычка: пока это возможно, везде использовать рекорды, а к классам переходить, если состояние изменяется. В моем клиенте для Постгреса примерно так и сделано. Из 150 классов почти все из них — записи, и только корневой класс
Connection— обычныйObject.Чтобы вы не подумали, что все так хорошо, вот ложка дегтя. Когда классы неизменяемы, часто нужен “такой же, но золотыми пуговицами”. Другими словами, получить клон экземпляра с измененным полем. Кложуристы поймут без слов:
(let [user {:name "Ivan" :age 10}] (assoc user :name "New")) ;; {:name "New", :age 10}На мой взгляд, было бы логичным, если бы компилятор генерил методы
.withNameи.withAge, которые принимают значение и возвращают клон с новым полем. Но их нет, а прописывать вручную — скучно: это экраны кода, где, вдобавок, легко ошибиться.Четыре года назад в Джаве сделали шаг в верном направлении. Хорошо, но мало. Не пора ли сделать еще? Глядишь, так и придем в светлое будущее.
Кстати, в Питоне тоже относительно недавно появились
data-классы. Неужели адепты ООП стали что-то подозревать? -
-
Фронтендеры
Выскажу тезис в отношении фронтендеров. Может, он не самый приятный, но неплохо упрощает дело. Тезис следующий: фронтендер мыслит npm-пакетами. В мире фронтендера любая задача, любая проблема решаются одним способом — пакетом из npm.
У тезиса несколько следствий. Во-первых, когда есть несколько способов решить задачу, фронтендер выбирает тот, для которого есть npm-пакет. При этом не важно, насколько способ оптимален и удобен другим участникам, например бекенду или пользователям. Есть пакет — дело в шляпе.
Во-вторых, если нужного пакета нет, берется максимально близкий к нему и задача подгоняется так, чтобы ему удовлетворять.
Стоит только принять тезис и следствия, как многое становится очевидным. Например, нелепые решения, особенности передачи данных, требования коллег.
Доказательств этому я повидал много, вот хотя бы одно.
Есть SPA-приложение для сотрудников. По нажатию кнопки нужно скачать с бекенда CSV-файл. Как его передать, если на сервере только REST и JSON? Как скачать файл, чтобы он не открылся в текущей вкладке?
Фронтендер загуглил “javascript csv on client” и нашел npm-пакет. Он принимает массив словарей, записывает их в CSV-строку и заставляет браузер ее “скачать”, то есть сохранить на диск. Бекендер пожал плечами, мол как скажешь — и отдал на фронт список мап. Это не его дело, фронтендер так попросил, пусть и разбирается.
Все это работало, пока строчек было сто-двести. Но однажды мне велели сделать выгрузку на двести тысяч записей. Я сделал по образцу, и тут-то браузер накрылся. Вкладка окирпичивается, ничего не работает.
Далее, я был единственным, кто задался вопросом: что делают люди с этим файлом? Оказалось, открывают в Экселе. Как я уже рассказывал, открывать CSV в Экселе — это играть в русскую рулетку. Эксель вечно путает разделитель полей — запятую или точку с запятой — и даже больше: эта опция зависит от локали. Поэтому открывая файл, половина людей видели слипшиеся поля и матерились.
У Экселя есть костыль: если в первой строке CSV написать
sep=;, то будет использоваться именно этот разделитель. Но оказалось, npm-пакет ничего про это не знает. Нужно контрибьютить и пинать автора, чтобы принял изменение и выкатил версию.Наконец, я спросил прямо: если пользователи открывают файл в Экселе, уж наверное им нужен файл xlsx, а не CSV? Так-то да, но пакета в npm, чтобы собрать эксельку на клиенте, нет, поэтому пролетаем.
В итоге я сделал вот что. На бекенде пишу нормальный Эксель-файл. Кладу его в S3 и получаю подписанный урл, который действует 15 минут. В HTTP-ответ отдаю джейсончик с этим урлом:
{"url": "https://acme.amazonaws.com/path/to/file.xlsx?...", "expires_at": "..."}На клиенте: получаю джейсончик, достаю урл. Потом:
- создаю невидимый элемент
<a href="...">с этим урлом - добавляю этот элемент в тело так, что его не видно
- имитирую клик по нему методом
.click()
В результате файл загружается автоматом. Ну или может появиться окно с вопросом, что делать с файлом.
Тот npm-пакет я к черту выбросил, потому что он банально не нужен.
Как я и говорил, все упирается в тезис из начала заметки. Фронтендер не понимает проблему, которую решает. Он не понимает в целом как обмениваться данными, как делать удобно другим — коллегам, пользователям. Он мыслит npm-пакетами и подгоняет условия задачи под те пакеты, которые нагуглил.
Я, кстати, вообще считаю, что фронтенд — это не программирование. Современный фронтендер занят тем, что передает результат из пакета А в пакет Б. Это не хорошо и не плохо, это просто факт. Примерно как сборка изделия из готовых частей.
Знание этого принципа, на мой взгляд, полезно в следующем. Выбирая решение, нужно проверить, что у фронта есть для него пакет. Нужно следить, чтобы коллеги выбрали максимально адекватный их них. Такой, чтобы не повесил браузер, не скачал 100 зависимостей вроде
is_number,leftpadи так далее.Короче, следить за ними, как за перспективными детьми, которые в любой момент могут попасть в дурную компанию.
Ну и порой подсказать фронтендерам, что задача решается не пакетом, а пятью строчками на чистом js. Часто они этого не знают.
- создаю невидимый элемент
Writing on programming, education, books and negotiations.